Machine learning is about forecasting. Forecasts, however, obtain their usefulness only through their evaluation. Machine learning has traditionally focused on types of losses and their corresponding regret. Currently, the machine learning community regained interest in calibration. In this project, we demonstrate conceptual equivalences of calibration and regret in evaluating forecasts.
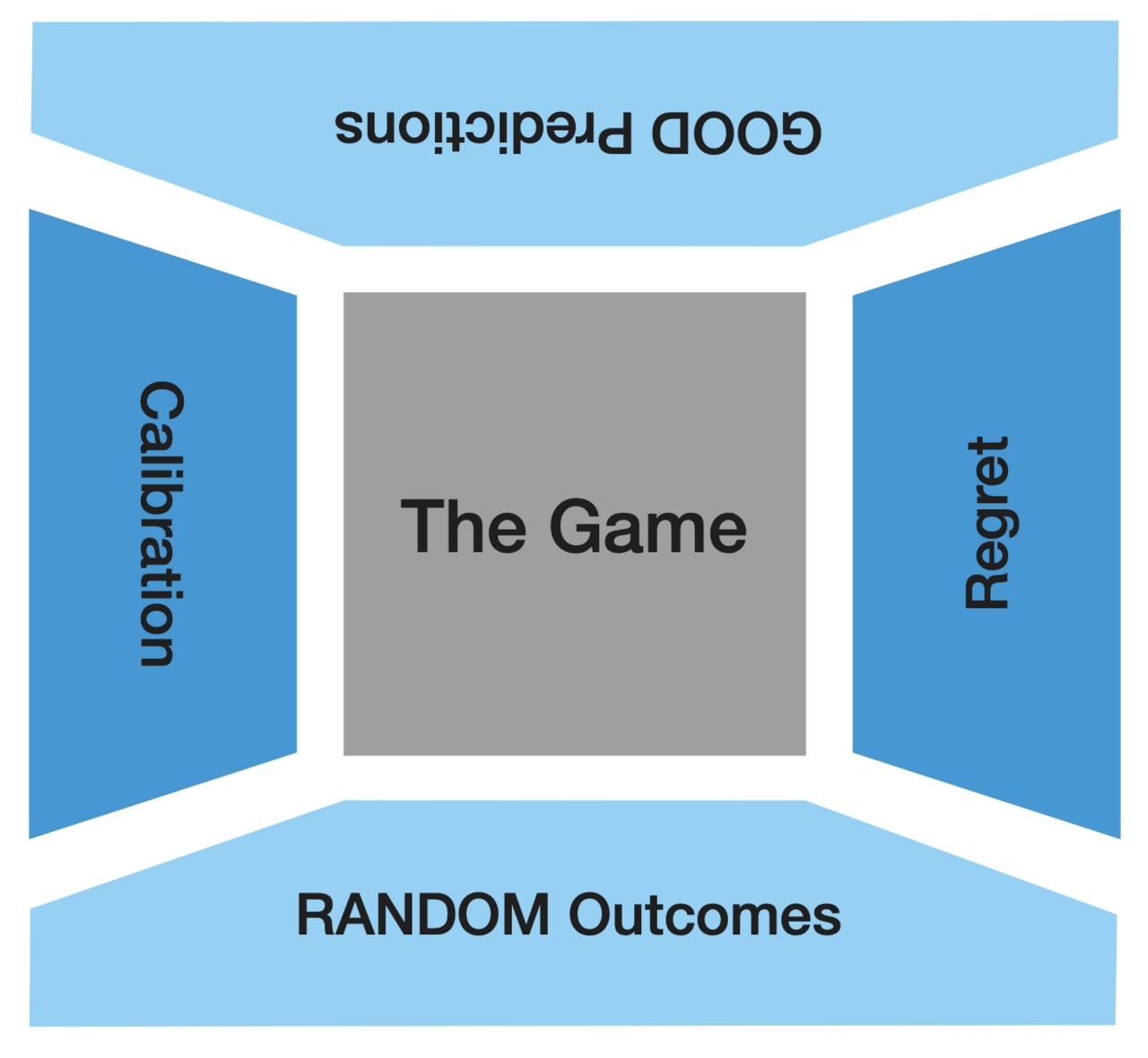
In addition, we frame the evaluation problem as a game between a forecaster, a gambler and nature. This game links evaluation of forecasts to randomness of outcomes. Random outcomes with respect to forecasts are equivalent to good forecasts with respect to outcomes. We call those dual aspects, calibration and regret, predictiveness and randomness, the four facets of forecast felicity.
For more details see [Four Facets of Forecast Felicity].